
Lightweight blasthole image detection and positioning method
-
摘要:
在岩巷掘进工作面爆破作业中,目前采用人工装药或由经验丰富的人员操作机械臂进行装药,作业的有效性和安全性难以保证。装药机械臂的智能化发展是实现掘进面爆破作业中药物填充操作安全高效运行的关键,而炮孔图像检测算法是装药机械臂智能化控制系统的核心算法。为实现装药机械臂的智能化控制,保证炮孔图像检测精度的同时降低控制装置的功耗,使装药机械臂嵌入式控制装置满足本质安全型电气产品的安全要求,提出了一种轻量化炮孔检测与定位算法Mv3-SCD。该算法在炮孔检测精度方面,针对炮孔受围岩背景、岩石阴影影响产生的误检现象,以及炮孔在图像中表现出上下文信息少、可识别特征有限导致的漏检问题,首先设计了一种炮孔检测头结构,通过使用高分辨率的检测头来减少过多的下采样导致的炮孔特征损失;然后引入了Mv3_Block使算法在浅层特征便具备较强的炮孔语义抽象能力,通过配合空洞金字塔池化模块增大感受野,以捕获复杂围岩背景下炮孔和岩石遮挡形成的阴影之间的细粒度差异特征;最后,为了提高炮孔边界框回归的准确率,对损失函数进行了优化。针对炮孔图像检测与定位算法网络模型参数量大、每秒帧数小的问题,提出了一种轻量级的Sc_C2f模块来对网络结构进行优化。为了验证算法的有效性,分别从主观和客观2个方面对Mv3-SCD系列进行了分析。与最小基线模型相比,Mv3-SCDn炮孔算法具有最优的炮孔检测效果,炮孔检测模型参数量下降了7.17%,检测速度提高了45.44%。实验结果表明,提出的算法能够有效提高智能装药机械臂的精准度和网络模型的轻量化程度。
Abstract:In blasting operations within rock tunnel excavation faces, the current practice of manual explosive charging or robotic arm operation by experienced personnel struggles to ensure both operational effectiveness and safety. The intelligent advancement of explosive-charging robotic arms is critical to achieving safe and efficient explosive filling in tunnel blasting operations, with the blasthole image detection algorithm serving as the core component of the intelligent control system for these robotic arms. To achieve intelligent control of the explosive-charging robotic arm, ensure the accuracy of blasthole image detection, and reduce the power consumption of the control device, enabling the embedded control device of the robotic arm to meet the safety requirements of intrinsically safe electrical products, a lightweight blasthole detection and localization algorithm Mv3-SCD, is proposed. In terms of blasthole detection accuracy, the algorithm addresses the issue of false detection caused by the influence of surrounding rock backgrounds and rock shadows, as well as the problem of missed detection due to limited contextual information and identifiable features of blastholes in images. Firstly, a blasthole detection head structure is designed, which utilizes a high-resolution detection head to reduce the loss of blasthole features caused by excessive downsampling. Secondly, the Mv3_Block is introduced to enable the algorithm to possess strong semantic abstraction capabilities for blastholes even at shallow feature levels. By incorporating an atrous spatial pyramid pooling module, the receptive field is expanded to capture fine-grained differences between blastholes and shadows formed by rock occlusion in complex surrounding rock backgrounds. Finally, the loss function is optimized to improve the accuracy of blasthole bounding box regression. To tackle the issues of large parameter size and low frames per second (FPS) in the blasthole image detection and localization algorithm network model, a lightweight Sc_C2f module is proposed to optimize the network structure. To validate the effectiveness of the algorithm, both subjective and objective analyses of Mv3-SCD are conducted. Compared with the minimum baseline model, the Mv3-SCDn blasthole algorithm has the best blasthole detection effect, the number of blasthole detection model parameters is reduced by 7.17%, and the detection speed is increased by 45.44%. Experimental results indicate that the proposed algorithm effectively enhances the precision of intelligent explosive-charging robotic arms and achieves a higher level of network model lightweighting.
-
0. 引 言
现阶段岩巷掘进工作面爆破作业的装药机械臂智能化程度较低,主要依赖于人工装药或由经验丰富的操作人员操作机械臂完成。然而完全依赖作业人员人眼识别炮孔并进行装药,不仅效率低,而且装药质量难以保障,易产生安全隐患,严重危害作业人员的生命安全[1-2]。提高岩巷掘进面爆破作业的安全性和效率的关键是提升装药机械臂的智能化水平。设计和开发精准的炮孔检测和定位算法是装药机械臂智能控制系统的核心,对于实现岩巷掘进面爆破作业的精准控制方面具有重要意义[3]。
在装药机械臂智能控制系统的研究中,一些基于深度学习的目标图像检测技术已被应用于炮孔检测。基于深度学习的目标图像检测方法可以分为以R-CNN系列[4-6]为代表的两阶段目标检测算法和以YOLO系列[7-12]为代表的单阶段目标检测算法。单阶段目标检测算法[13]具有速度快、计算资源少等优势。因此,单阶段目标检测算法近些年来成为国内外众多学者关注的热点,且在炮孔检测领域已取得了一定的成果。张也[14]提出了基于YOLOv2和SSD512的煤矿井下炮孔识别算法,对基于图像的炮孔识别算法进行了研究,但该算法的复杂度较高,难以在装药机械臂的嵌入式控制装置系统中实现。陈显等[15]采用支持向量机的方式进行智能炮孔识别。该方法充分考虑了岩石划分的模糊性,获得了较好的区别度,但泛化能力较差,对大规模样本的训练时间和计算复杂度会显著增加,且对于小尺寸炮孔的检测效果不佳,影响了检测精度和速度。郭洪雨等[16]提出基于ResUNet深度网络的围岩炮孔留痕检测方法,该方法能够高效、精确的评估隧道爆破后的炮孔留痕率,提升了工程质量检查效率,但该方法因存在多层堆叠的卷积层,增加了计算的复杂度,无法满足实时性的需求。张万志[17]提出了基于改进Faster R-CNN的岩质隧道工作面炮孔识别技术,实现对单个炮孔和多个困难炮孔快速高效的识别与定位。苏钰桐等[18]使用YOLOv3算法矿井目标检测模型,用于识别煤岩炮孔图像中的裂缝,但该方法使用数据集样本和种类较少,泛化性不足,鲁棒性弱,且网络结构复杂,参数量和计算量较大。ZHANG等[19]提出了一种半监督语义分割的炮孔检测方法,利用残差连接和扩展卷积层下采样,并通过注意力互补模块获取特征图,且在解码过程中使用金字塔场景解析来实现炮孔分割,该方法减少了对标注数据集的依赖,但其参数量和复杂度依然较大,消耗了大量的计算资源。AKINLAR等[20]提出了无参数边缘绘制(EDPF)算法,使用无参数边缘段检测器实现了炮孔的实时检测。因此被称为EDCircles,但它通常对于有缺陷的炮孔检测是无效的。ZHAO等[21]提出了金字塔场景解析网络(PSPNet),提高了网络对较复杂场景的感知能力,但其依赖于金字塔结构的提取特征能力,导致模型在实际应用中出现漏检或误检问题。岳中文等[22]提出一种基于深度学习的轻量化炮孔检测方法,采用多尺度并行结构,具有较高的准确度和自动化程度,但该实验数据集样本规模较小,不够多样,进而无法充分验证算法的泛化性能。
考虑到相机在采集图像时,炮孔大小会随相机与围岩表面的距离产生变化。当相机距离围岩表面较远时,炮孔在图像中表现出极小目标的特性;当相机距离围岩表面较近时,炮孔表现出大目标的特性。具有极小目标特性的炮孔和具有大目标特性的炮孔将产生显著差异的上下文信息,易导致炮孔漏检。此外,与其他检测目标相比,炮孔易受围岩背景和岩石阴影等因素的影响,难以提取到具有鉴别力的特征,易导致炮孔的误检。由于掘进工作面是矿井生产中最先开掘出的巷道,掘进工作面中尚无法建立完整的通信网络,存在无法在地面远端对装药机械臂进行智能化操作控制的问题,需在嵌入式系统或边缘计算中部署模型。要实现在煤矿井下爆炸性环境中对装药机械臂的智能化控制,解决控制装置的防爆问题是目前的关键任务,最有效的途径是降低装药机械臂的功耗,以使装药机械臂满足本质安全型电气产品的要求。其中,炮孔图像检测算法是装药机械臂智能化控制系统的核心算法,实现炮孔图像检测算法的轻量化是降低装药机械臂功耗的重要途径,通过减少网络模型参数量和降低计算复杂度来提高模型轻量化程度,从而降低功耗。这就对装药机械臂智能控制系统的炮孔检测和定位算法的轻量化提出了较高要求。
为解决上述问题,笔者提出一种高精度且轻量化的炮孔检测与定位算法Mv3-SCD。根据图像中炮孔表现为极小目标的特性,Mv3-SCD首先设计一种检测头结构,通过使用高分辨率的检测头来减少过多的下采样导致的炮孔特征损失。另外,传统卷积操作的感受野有限,通常需要堆叠较多的卷积层才能提取有效的全局语义特征,为此,笔者提出Mv3_Block,以同时提取局部和全局特征,使炮孔检测算法在浅层特征就具有较强的炮孔识别能力,进一步提高了高分辨率检测头的检测准确率。此外,笔者还引入了空洞金字塔池化模块[23]来增大感受野,提高低分辨率检测头的准确率。在此基础上,笔者基于YOLOv8中[24]的C2f模块提出了轻量级的Sc_C2f模块来减少参数量和计算量,实现了模型的轻量化。最后,笔者在训练时采用了优化的损失函数,提高了预测边界框回归的准确度,实现了炮孔检测算法的精准定位。
1. 炮孔图像检测模型
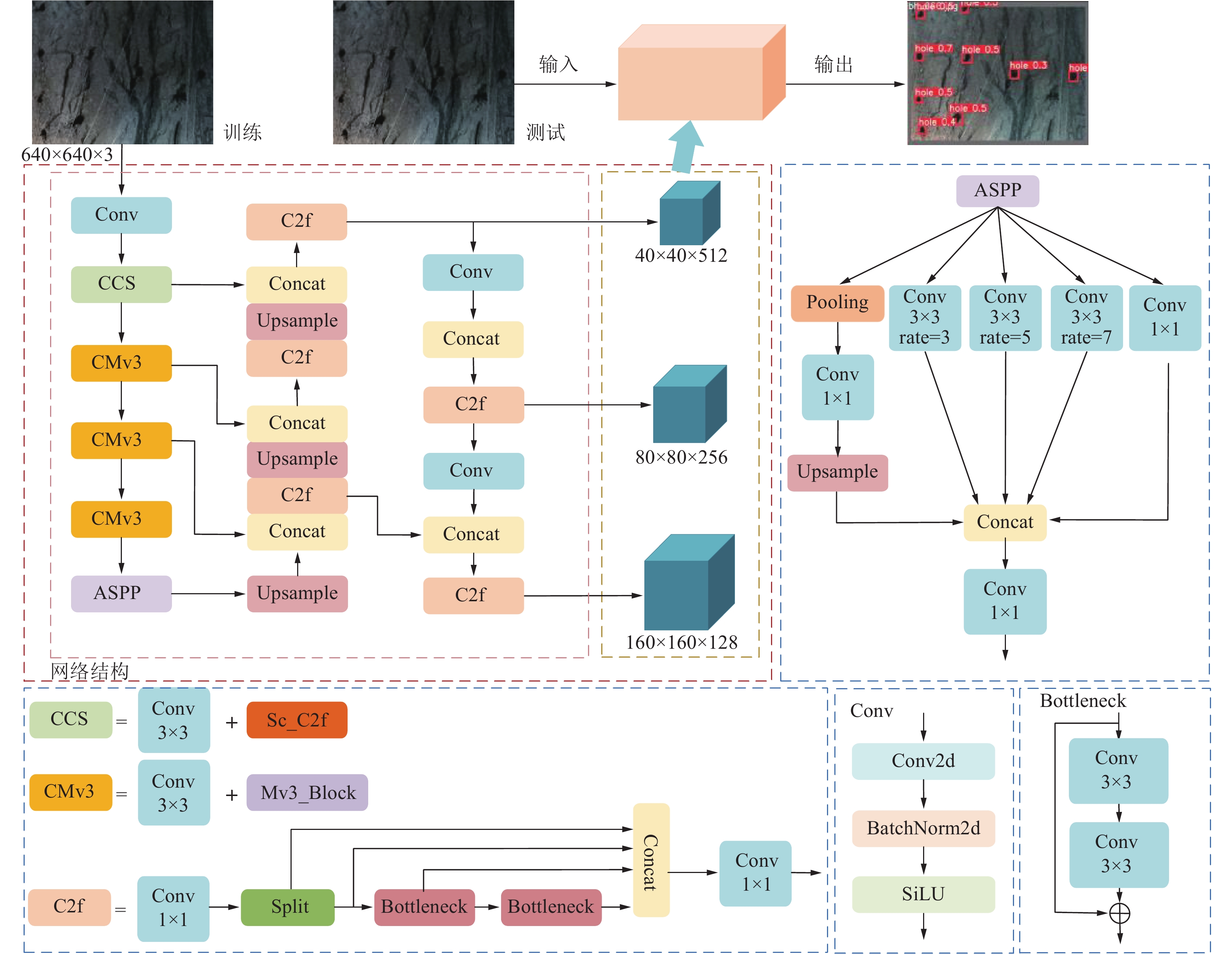
针对复杂围岩背景和岩石阴影下炮孔图像的上下文信息较少、可识别特征有限所导致的误检漏检,以及基于深度学习的网络模型参数量大、计算性能差的问题[25-26],笔者提出了轻量化炮孔检测与定位算法Mv3-SCD,网络结构如图1所示。
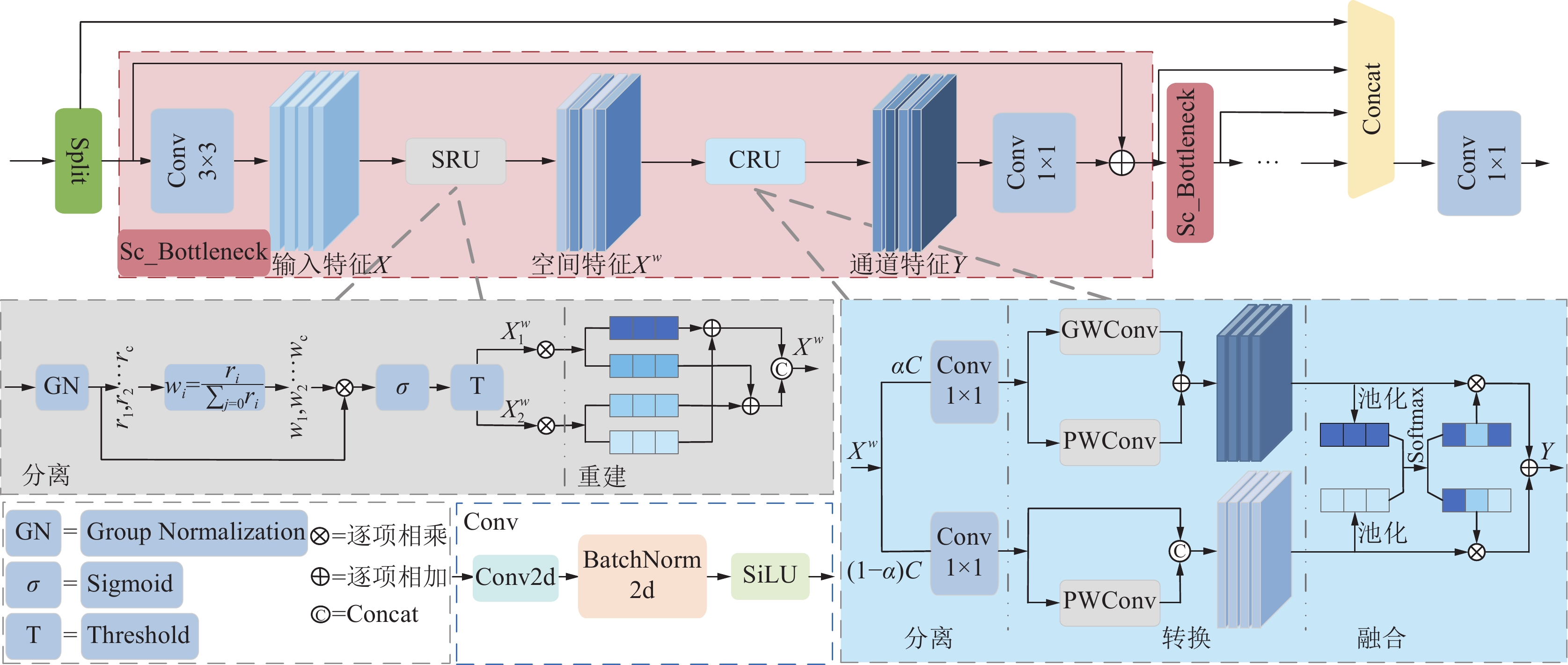
![]() 图 1 轻量化炮孔检测与定位算法Mv3-SCD结构Figure 1. Lightweight blasthole detection and localization algorithm Mv3-SCD structure
图 1 轻量化炮孔检测与定位算法Mv3-SCD结构Figure 1. Lightweight blasthole detection and localization algorithm Mv3-SCD structure该网络主要由主干网络和检测头2部分组成。首先,将训练集中的图像分辨率调整为1 280×720作为网络的输入,经过一层卷积和CCS模块来进行浅层特征提取,其中CCS模块包括一层3×3的卷积和一个Sc_C2f模块。Sc_C2f模块为轻量级的浅层特征提取模块,能够减少网络模型参数量和计算复杂度。然后,采用3个CMv3模块挖掘图像中的局部特征和全局特征,该模块主要包括一层3×3卷积和一个Mv3_Block。图像特征提取的最后阶段,为了获得炮孔图像的高级语义特征,采用了空洞金字塔池化模块来增大模型感受野。然后,为了利用不同层次的特征进行炮孔检测,采用由上采样和特征拼接操作组成的特征金字塔进行多尺度融合。最后,选择特征金字塔的1/4、1/8和1/16分辨率的特征,经过检测头进行炮孔的边界框坐标以及置信度等预测。笔者提出的Mv3-SCD算法意在提高特征利用率,增加浅层特征的表现力,在保证精度和特征提取能力的前提下降低网络模型参数量和计算复杂度。
1.1 检测头网络
多数炮孔表现出极小目标的特性,且在图像中分布不均。最先进的目标检测模型YOLOv8包括80×80、40×40和20×20分辨率的检测头。然而,炮孔作为极小目标在20×20分辨率的检测头中特征不明显,过多的下采样会使原本具有较少特征的炮孔产生特征丢失的问题,从而导致炮孔漏检。因此,笔者提出一种新的检测头结构,如图1所示。该结构将20×20的P5检测头以及相应的特征提取和融合层删除,并设计了160×160的P2检测头。通过将上采样的语义特征与网络结构中的P2特征进行特征融合,并输入160×160的P2检测头,使检测模型在表现出极小目标特性的炮孔检测中产生更好的检测性能。具体结构数据见表1。
表 1 检测分支输出结果Table 1. Detection branch output results检测头 检测分支 输出 YOLOv8 P3 80×80×256 P4 40×40×512 P5 20×20×1 024 Ours P2 160×160×128 P3 80×80×256 P4 40×40×512 1.2 主干网络
1.2.1 Mv3_Block
围岩背景复杂,在光照的影响下,炮孔与岩石遮挡形成的阴影差异较小,这使得检测模型在围岩背景下易产生炮孔误检问题。传统卷积操作虽然能够提取细粒度的炮孔特征,但无法产生具有感知全局上下文的语义特征,对于炮孔的形状以及岩石遮挡所形成的阴影鉴别力较差,易导致炮孔误检。Transformer[27]可以实现全局特征的提取,对于炮孔的形状和炮孔与阴影之间的差异特征的提取能力较强,因此笔者提出了Mv3_Block,结构如图2所示。Mv3_Block能够同时提取局部特征和全局特征并进行有效融合,不仅可以多层次挖掘炮孔和阴影之间的差异,而且有利于获得细粒度的炮孔特征,提高炮孔检测的准确率。此外,如图1所示,将该模块作用于主干网络的浅层特征,让浅层特征产生具有鉴别力的语义特征,有利于对极小目标的检测。
给定输入Mv3_Block的中间视觉特征${f_1} \in {\mathbb{R}^{H \times W \times C}}$,其中H、W和C分别代表空间的高度、宽度和通道数。首先通过3×3的深度可分离卷积(DWConv)和1×1的标准卷积(Conv)来提取局部特征。过程表示为
$$ {f_2} = {\mathrm{Conv}}{_{1 \times 1}}({\mathrm{DWConv}}{_{3 \times 3}}({f_1})) $$ (1) 由于Transformer中自注意力机制的计算量随输入分辨率呈二次方增长,为了构建轻量化的炮孔检测与定位算法,笔者使用一种线性Transformer实现全局特征的提取[28]。然后,使用特征拼接操作将全局特征与局部特征f2进行拼接,并使用卷积核为1×1的卷积进行特征融合。该过程表示为
$$ {f_3} = {\mathrm{Conv}}{_{1 \times 1}}\left( {{\mathrm{Concat}}\left( {{f_2},{\mathrm{LinearTrans}}\left( {{f_2}} \right)} \right)} \right) $$ (2) 式中:Concat为特征拼接操作;f3为融合后的特征。
最后,笔者将融合后的特征与输入特征进行逐元素相加形成残差结构,输出结果fout。此操作有利于梯度的传播,促进模型收敛。该过程表示为
$$ {f_{{\mathrm{out}}}} = {f_3} + {f_1} $$ (3) 1.2.2 Sc_C2f模块
装药机械臂智能控制系统应用于煤矿井下爆炸环境中,无法在地面远端对装药机械臂进行智能化操作控制,需在移动设备、嵌入式系统或边缘计算中部署模型,同时降低控制装置的功耗,满足煤矿井下掘进面对电气的安全要求。因此,对模型大小、检测实时性和网络模型参数量均有较高要求。为了实现装药机械臂智能控制系统炮孔检测和定位算法的轻量化设计,需要尽可能降低炮孔检测和定位算法的参数量和计算复杂度,因此,笔者提出一种高效的通道和空间重构模块Sc_C2f。该模块不同于YOLOv8中的C2f模块,基于C2f模块对其重新进行设计[24],该模块减少了C2f模块中的冗余特征,增强重要特征的学习,在大幅降低参数量的同时保证了炮孔检测的准确率。
Sc_C2f模块的结构如图3所示。给定中间视觉特征,Sc_C2f模块首先按通道将其分为2组。其中一组直接输入后续的特征拼接操作,将另一组特征通过n个Sc_Bottleneck进行提取特征。为了实现浅层特征和深层特征的融合,每个Sc_Bottleneck的输出都将输入至后续的特征拼接操作。最后将拼接后的特征通过1×1的卷积实现多层特征融合和通道维度变换,使输出特征的维度和输入相同。
Sc_Bottleneck主要包含3×3的卷积以及Scconv中[29]的空间重构单元(SRU)和通道重构单元(CRU)。给定输入特征$X \in {\mathbb{R}^{H \times W \times C}}$,利用Scconv中的SRU,首先按照归一化权重值${W_r} = \{ {\omega _1},{\omega _2},\cdots,{\omega _C}\} $的大小,将信息量丰富的特征图和信息量较少的特征图分离,并与空间内容相对应,从而抑制无关空间冗余;其次,将加权后信息量较多的特征图$X_1^\omega $与信息量较少的特征图$X_2^\omega $交叉相加,得到空间细化的特征图${X^\omega }$。在Scconv的CRU中,首先将空间细化的特征图${X^\omega }$分割成$\alpha C$和$(1 - \alpha )C$等2个部分($\alpha $为超参数且$0 \leqslant \alpha \leqslant 1$),并进行压缩;然后,利用分组卷积(GWConv)[30]减少参数量和计算量,同时利用逐点卷积[31](PWConv)保持信息在通道中的流动性,并减少过滤器实现降维;最后,通过池化和Softmax操作将全局空间信息和通道信息结合起来,得到输出特征Y。用于信息量分离特征图的归一化权重值${W_r} = \{ {\omega _1},{\omega _2},\cdots,{\omega _C}\} $的计算为
$$ {W_r} = \{ {\omega _i}\} = \frac{{{r_i}}}{{\displaystyle\sum\limits_{j = 1}^C {{r_j}} }},i,j = 1,2,\cdots,C $$ (4) 式中:i为当前权重的索引;j为求和时的遍历索引;C为元素个数;$r \in {\mathbb{R}^C}$为可训练仿射变换,r越大则像素之间的变化越大,空间信息也越丰富。
1.2.3 空洞金字塔池化模块
通过相机采集的图像中的炮孔大小会随相机与围岩表面的距离发生变化,表现出极小目标的特性和大目标的特性。具有极小目标特性的炮孔和具有大目标特性的炮孔将产生显著差异的上下文信息,易导致炮孔漏检。为了进一步提高主干网络对大目标的特征抽象能力,笔者采用空洞金字塔池化模块来进一步提高高级特征的感受野,其结构如图1所示。
空洞金字塔池化模块主要由一个1×1的标准卷积,3个3×3的空洞卷积和一个自适应池化组成。空洞卷积通过设置膨胀因子控制卷积过程中的边缘填充和扩张来获取更大的感受野。笔者使用了3个不同膨胀率的空洞卷积来捕获不同尺度感受野的特征,增强了模型对不同距离拍摄的炮孔的上下文感知能力。自适应池化操作将特征图的分辨率压缩至1×1以提取全局特征,这样有利于提升模型对输入图像的整体语义感知能力。最后将所有尺度的特征通过特征拼接和1×1卷积进行特征融合和通道维度变换。
1.3 优化损失函数
上述模块的加入能够有效解决炮孔的误检和漏检问题,提高炮孔检测的准确率,装药机械臂受控于智能控制系统进行装药作业,炮孔的准确定位同样具有重要的意义。炮孔检测与定位算法能够准确给出炮孔的位置信息,并根据其准确尺寸可以为后续装药机械臂的精准填充奠定基础。损失函数作为训练炮孔检测与定位算法时度量预测框和真实标注框之间差异的重要依据,可以有效约束炮孔检测与定位算法对于边界框的回归,进而给出准确的炮孔位置信息。
大多数边界框回归损失函数面对与真实标注框具有相同宽高比但尺寸不同的预测框时,无法达到理想的约束效果,从而产生位置误差。针对炮孔检测边界框回归问题,提出了使用MPDIoU[32]优化损失函数的策略。具体而言,MPDIoU在IoU的基础上进行了优化,IoU通过预测框与真实框的交集面积与并集面积的比值来衡量重合程度,但其在预测框与真实框完全不相交时无法提供有效的优化信息。然而,MPDIoU是基于最小点距离的边界框相似度进行比较度量的,能够简化2个边界框之间的相似性比较,可以适应重叠和不重叠的边界框回归。此外,基于MPDIoU的损失函数${{{\mathcal{L}}}_{{\mathrm{MPDIoU}}}}$考虑了真实框与预测框之间的重叠面积、中心点距离以及边界框的宽高比,优化了最小预测边界框,简化了计算过程。其中,IoU度量可以表示为
$$ {\mathrm{IoU}} = \frac{{{b^{{\mathrm{gt}}}} \cap b}}{{{b^{{\mathrm{gt}}}} \cup b}} $$ (5) 式中:bgt为真实边界框;b为预测边界框。
一般来说,使用左上角和右下角的坐标来定义一个唯一的矩形。将最小化预测边界框A和真实边界框B之间的左上角点${A_{\mathrm{l}}}(x_1^A,y_1^A)$,${B_{\mathrm{l}}}(x_1^B,y_1^B)$和右下角点${A_{\mathrm{r}}}(x_2^A,y_2^A)$,${B_{\mathrm{r}}}(x_2^B,y_2^B)$之间的距离表示为
$$ d_1^2 = {(x_1^B - x_1^A)^2} + {(y_1^B - y_1^A)^2} $$ (6) $$ d_2^2 = {(x_2^B - x_2^A)^2} + {(y_2^B - y_2^A)^2} $$ (7) $$ \begin{aligned} {\mathrm{MPDIoU}} = & \frac{{A \cap B}}{{A \cup B}} - \frac{{d_1^2}}{{{w^2} + {h^2}}} - \frac{{d_2^2}}{{{w^2} + {h^2}}} =\\ & \frac{{A \cap B}}{{A \cup B}} - \frac{{d_1^2}}{{{d^2}}} - \frac{{d_2^2}}{{{d^2}}} \\ \end{aligned} $$ (8) 式中:w和h分别为预测边界框的宽度和高度。
通过优化训练过程并最小化定义的损失函数,使得模型输出的每个预测边界框能够更好地拟合对应的真实边界框,从而提升目标检测的准确性。在真实边界框和预测边界框不重叠的情况下,即IoU=0,MPDIoU损失${{{\mathcal{L}}}_{{\mathrm{MPDIoU}}}}$可以简化为
$$\begin{split} {\mathcal{L}}_{{\mathrm{MPDIoU}}}=1-{\mathrm{MPDIoU}} = 1+\frac{{d}_{1}^{2}}{{d}^{2}}+\frac{{d}_{2}^{2}}{{d}^{2}} \end{split}$$ (9) 2. 实验结果与分析
2.1 数据采集
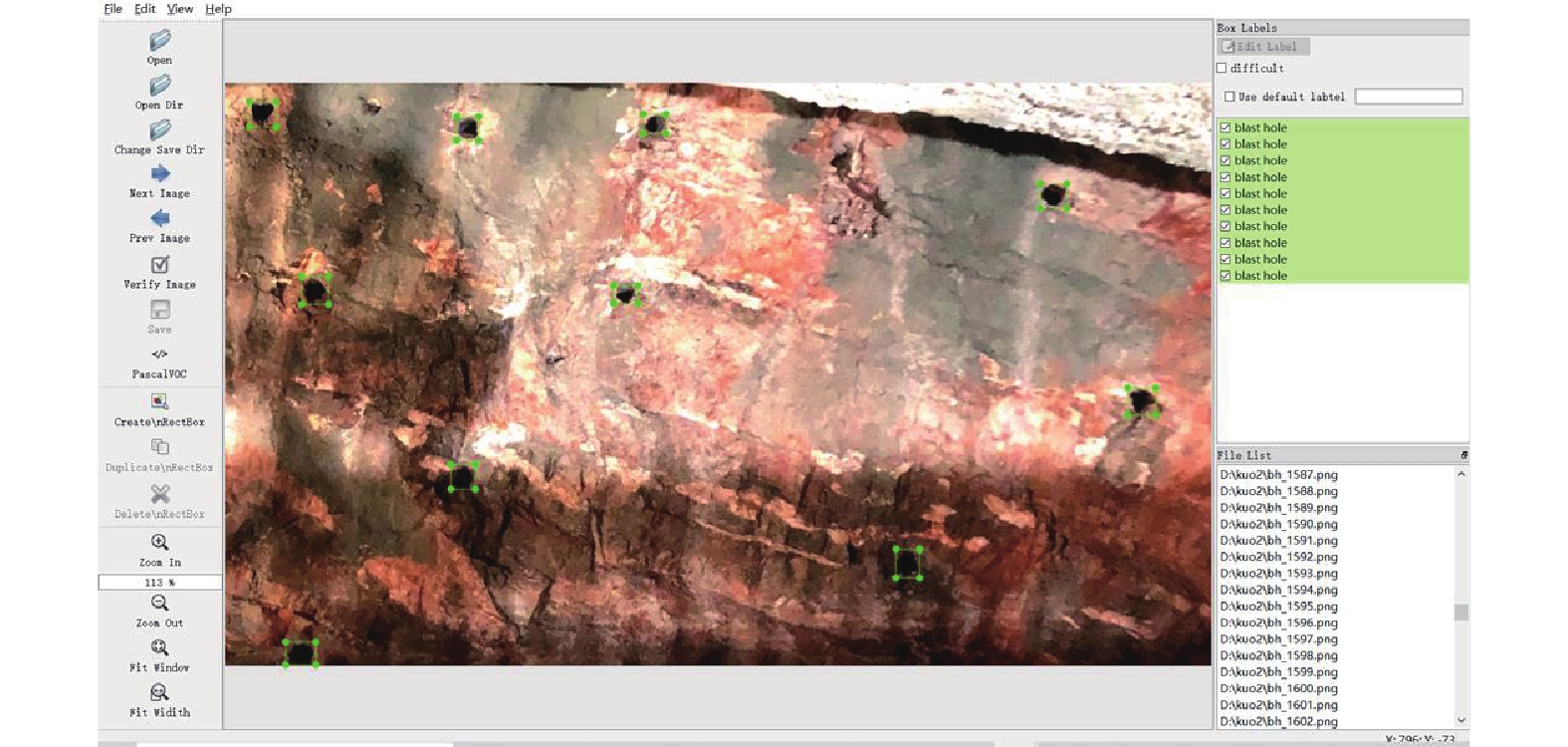
为保证炮孔数据集的可靠性和真实性,笔者所使用数据集采集自安徽省淮南市某矿工作面,并将采集数据集命名为CUMTB-BID (China University of Mining And Technology Beijing-Blasthole Image Detection)。CUMTB-BID数据集使用本安型防爆相机型号ZHS2420并搭载新型地标本安型LED闪光灯和本安型KTW280防爆手机拍摄数据集。相机最大分辨率为6 000×4 000,手机最大分辨率为2 340×1 080。实验中,将所有图像分辨率调整为1 280×720。下图展示了不同条件下采集的部分样本(图4)。
![]() 图 4 不同条件下采集的部分样本Figure 4. Part of the sample maps collected under different conditions
图 4 不同条件下采集的部分样本Figure 4. Part of the sample maps collected under different conditions笔者采用LabelImg软件对炮孔图像进行标注,标记以矩形框的形式完成。
使用LabelImg软件时,将图像标注为YOLO格式,得到txt文件,如图5所示。txt文件中第1列表示对象类型,第2列和第3列表示标记的矩形框的中心点坐标,第4列和第5列分别表示矩形框的宽度和高度。
2.2 实验配置
实验所使用的服务器配置为i9-10900K CPU,64GB RAM和NVIDIA RTX
3090 GPU。深度学习框架为PyTorch 1.13。训练时将输入图像设置为1 280×720,批处理大小为8,模型训练次数epoch设置为300,初始学习率为0.001。笔者将CUMTB-BID数据集中的4 985张图像和对应的标签按8:2的比例随机划分。划分后的训练集包含3 988对样本,验证集包含997对样本。此外,笔者采用了水平翻转和马赛克增强,其中,马赛克增强采用mixup方式,将样本随机裁剪并按比例与原样本进行混合。2.3 评价指标
笔者使用mAP@0.5和mAP@0.5_0.95作为评价指标来评价所提出的方法在不同条件下的检测性能。mAP@0.5指IoU阈值为0.5时平均精确度,其数值越大代表精度越高。mAP@0.5_0.95表示阈值从0.5到0.95,步长为0.05上的平均精度,其数值越大,模型性能越好。笔者只含有炮孔这一个类别,所以有mAP=AP。计算公式为
$$ \left\{\begin{array}{l} P = \dfrac{{{\mathrm{TP}}}}{{{\mathrm{TP}} + {\mathrm{FP}}}} \times 100\% \\ R = \dfrac{{{\mathrm{TP}}}}{{{\mathrm{TP}} + {\mathrm{FN}}}} \times 100\% \\ {\mathrm{mAP}} = {\mathrm{AP}} = \displaystyle\int_0^1 {P(R)d(R)} \end{array}\right.$$ (10) 式中:TP、FP和FN分别为正确预测结果数量、误检结果数量和漏检结果数量;P (Precision)和R (Recall)分别为精确率和召回率。
衡量网络模型轻量化的评价指标常用网络模型参数量(Params)、每秒帧数(FPS)和浮点运算数。笔者采用网络模型参数量和每秒帧数的大小来衡量笔者所提网络结构的轻量化程度,即网络模型参数量越小且每秒帧数越大,表示单位时间内可检测的图片数量越多,模型速度越快,计算复杂度和存储空间越少,则模型轻量化程度越高。网络模型参数量通常是指模型的可训练参数,对于输入为Hin × Win × Cin的特征图,卷积核大小为k×k时,得到输出特征图大小为Hout × Wout × Cout的卷积操作,其参数量(Params)的具体表达为
$$ {\mathrm{Params}} = \left( {k \times k \times {C_{{\mathrm{in}}}} + 1} \right) {C_{{\mathrm{out}}}} $$ (11) 每秒帧数(FPS)的具体表达为
$$ {\mathrm{FPS}} = \frac{1}{T} $$ (12) 式中:T为检测时间。
2.4 实验结果及分析
为了验证笔者所提算法的优势,在相同数据集和配置环境下,将笔者所提算法与YOLOv8系列算法进行客观指标对比,实验的详细结果见表2。
表 2 客观指标对比结果Table 2. Objective index comparison results模型 参数量/M mAP@0.5/% mAP@0.5_0.95/% 每秒帧数 YOLOv8n 3.110 79.8 41.6 108.31 Mv3-SCD-nano 2.887 89.7 45.8 157.53 YOLOv8s 11.126 82.5 42.7 105.29 Mv3-SCD-small 10.578 90.6 44.9 132.78 YOLOv8m 25.840 83.9 44.6 98.75 Mv3-SCD-medium 23.273 90.9 45.3 117.28 YOLOv8l 43.631 84.3 45.9 89.98 Mv3-SCD-large 38.194 91.1 46.2 95.84 通过表2中的实验可知,在相同的实验数据集下,笔者所提出的Mv3-SCDn算法获得了更高的准确性、更快的检测速度和更少的参数量。相较于Mv3-SCDl和Mv3-SCDm,它们虽然精度较高,但参数量过大,且检测速度较慢,不能够满足边缘设备对炮孔检测算法的轻量化的要求。综合实验数据和对比分析,笔者所提出的Mv3-SCDn算法效果最好,且参数量最小,检测速度最快,检测精度较高。
如图6中的炮孔检测结果可以看出,由于炮孔区域与围岩背景颜色相近,难以提取到具有鉴别力的炮孔特征,导致YOLOv8系列模型在检测图像中表现为极小目标的炮孔时,存在检测精度较低、质量较差以及容易漏检的问题。由图6a组实验结果可以看出,受岩石阴影遮挡的影响,炮孔区域中亮暗差异明显,使用本章所提方法增强了阴影区域炮孔的特征表达能力,使模型更加有利于关注炮孔部分,从而提升了检测效果。由图6b组实验结果可以看出,由于凹凸不平的围岩断面造成的炮孔边缘模糊,难以提取清晰的边缘特征且增加了纹理复杂度的问题,本章引入了Mv3_Block模块,使炮孔浅层特征便具备较强的语义感知能力,通过配合空洞金字塔池化模块增大了感受野,以捕获凹凸不平的围岩断面背景下炮孔的细粒度差异特征,有效改善了炮孔的检测效果。由图6c组实验结果可以看出,由于人工光照不均匀造成的炮孔目标区域清晰度较低的问题,本章方法引入了空洞金字塔池化模块,增加了各层网络的感受野,获得了更细粒度的多尺度特征,在一定程度上减轻了人工光照不均匀造成的影响,有效提升了炮孔的检测精度。综上所述,Mv3-SCD算法提供了更多细节特征,具有更好的综合性能,因此Mv3-SCD更适用于岩巷掘进工作面的炮孔图像检测。
2.5 消融实验
笔者为进一步提升炮孔检测模型的性能,本章对分辨率分别为80×80,40×40和20×20的检测头结构进行了优化,删除了20×20的P5检测头和相应的特征提取和融合层,并设计了160×160的P2检测头,解决了炮孔检测和定位算法的炮孔漏检问题。消融实验见表3,使用笔者设计的检测头结构可以使改进后的炮孔检测和定位算法在mAP@0.5、模型参数、mAP@0.5_0.95和检测速度之间实现很好的平衡,达到最优检测性能。由表3可知,笔者设计的检测头结构使得炮孔细节特征的提取更加丰富,此外,降低了炮孔检测和定位算法中炮孔的漏检问题,使得mAP@0.5_0.95提升了1.33%,参数量降低了3.34%且检测速度提升了4.60%。
表 3 检测头消融实验结果Table 3. Head ablation experimental results检测头 输出 mAP@0.5/% mAP@0.5_0.95/% 参数量/M 检测速度/FPS YOLOv8 80×80×256 89.3 45.2 3.110 108.31 40×40×512 20×20×1 024 Ours 160×160×128 89.6 45.8 3.006 113.29 80×80×256 40×40×512 为了验证笔者所提算法中各模块的有效性,采用控制模块变量的方式进行一系列实验对比。具体而言,以YOLOv8n为基准模型引入消融实验,分别评估Mv3_Block、Sc_C2f模块、空洞金字塔池化模块和损失函数(MPDIoU)在不同组合情况下的性能表现。下表为消融实验结果(表4)。
表 4 模块消融实验结果Table 4. Module ablation experimental resultsMv3_Block Sc_C2f 空洞金字塔池化模块 MPDIoU 参数量/M mAP@0.5/% mAP@0.5_0.95/% 检测速度/FPS 3.110 79.8 41.6 108.31 √ 3.274 86.8 44.4 132.27 √ 1.821 82.1 43.0 107.47 √ 3.112 85.9 43.9 101.01 √ √ 2.872 86.3 43.7 119.05 √ √ 3.298 89.4 45.1 128.83 √ √ 2.781 85.6 42.8 123.46 √ √ √ 2.981 89.3 44.9 159.67 √ √ √ √ 2.887 89.7 45.8 157.53 通过上表消融实验结果可以看出,Mv3_Block、Sc_C2f模块、空洞金字塔池化模块和损失函数(MPDIoU)对提高模型的mAP@0.5和检测速度能够产生积极作用,Mv3-SCDn几乎在所有实验数据的比较中都达到了最佳性能。具体而言,当在基准网络模型中加入Mv3_Block,其mAP@0.5提升了8.77%,检测速度提升了22.12%,说明Mv3_Block可以有效提取浅层炮孔特征;当在基准网络模型的基础上引入Sc_C2f模块,其mAP@0.5提升了2.88%,参数量降低了41.45%,验证了Sc_C2f模块可以有效的降低参数量和计算量;当空洞金字塔池化模块作用于基准网络模型后,使mAP@0.5提升了7.64%,证明空洞金字塔池化模块能够有效捕获不同尺度的空间信息,扩大感受野。当同时加入4个模块时,该模型的综合性能达到最佳,相比于基准网络模型,Mv3-SCDn炮孔检测模型的mAP@0.5提升了12.41%,检测速度提升了45.44%,参数量降低了7.17%。由此可见,笔者算法在保持高检测精度的同时大幅度降低了参数量,提升了检测速度,满足了实时性的要求。
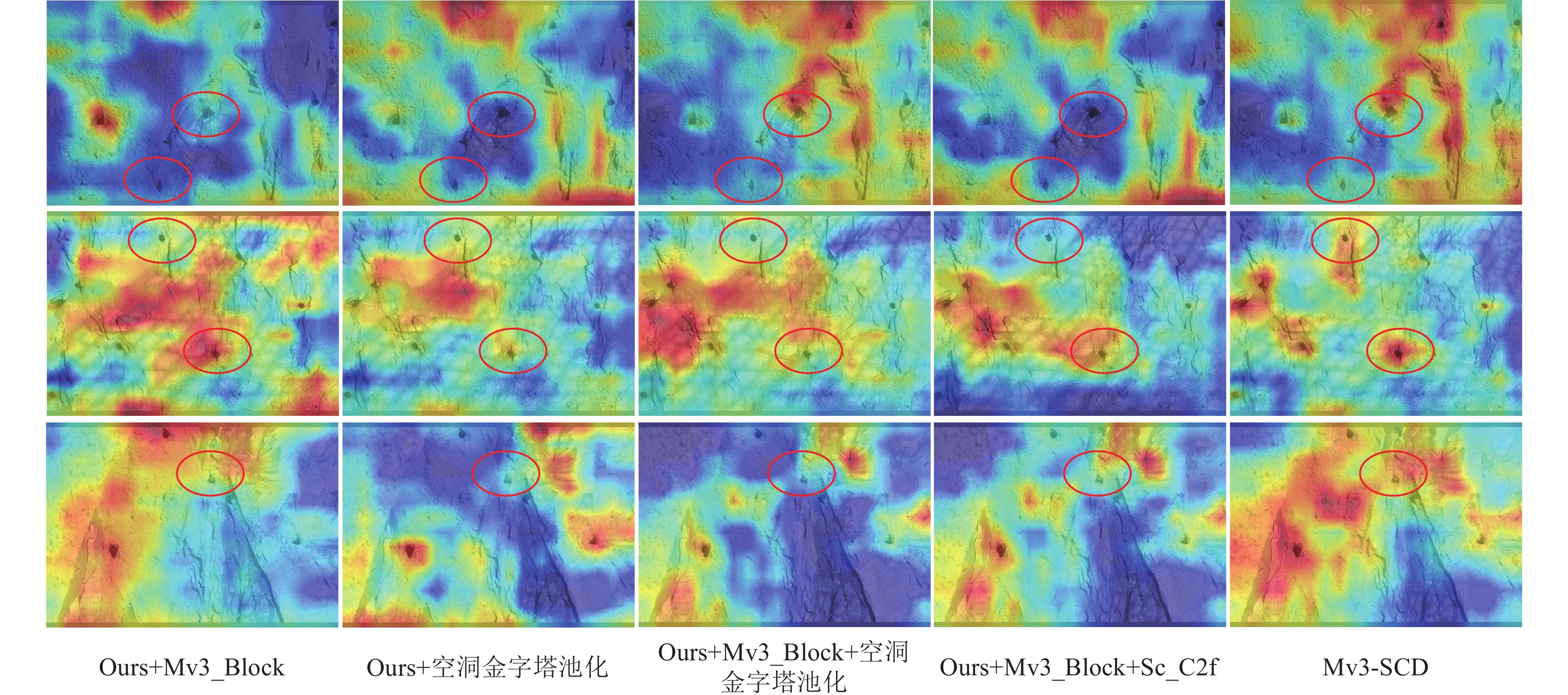
如图7所示展示了分别加入Mv3_Block、Sc_C2f模块和空洞金字塔池化模块的主干网络在最后一层提取的炮孔特征可视化特征图结果。在可视化特征图中,红色椭圆框标注了模型对炮孔注意力具有显著差异的区域,颜色显示越鲜艳,表示预测置信度越高,检测炮孔的精确率也越高。加入Mv3_Block后,炮孔所在区域的敏感程度明显高于仅加入空洞金字塔池化模块的主干网络,使得存在炮孔的区域颜色更加明亮。本章所提出的Mv3-SCD方法可视化对比图清晰的展示了这一优势,炮孔所在区域的颜色更加明亮,覆盖面积更大,置信度更高。这表明该方法显著提升炮孔的检测精度。因此Mv3-SCD更适用于岩巷掘进面的炮孔检测场景。
3. 结 论
1)设计一种检测头结构,通过使用高分辨率的检测头来减少过多下采样所导致的炮孔特征损失,并降低炮孔的漏检率。其中,mAP@0.5_0.95和检测速度分别提升了1.33%、4.6%,有效提升炮孔的检测精度。
2)采用Mv3_Block和空洞金字塔池化模块对扩大感受野和提取局部和全局的语义信息效果突出,将图像的浅层细节信息和深层语义信息相融合,能够减少炮孔的误检,使炮孔检测和定位算法的平均检测精度达到了89.7%,有效改善对于极小目标的检测效果。
3)对比现阶段的YOLOv8系列算法,笔者所提出的Sc_C2f模块大幅度降低了网络模型参数量。相比于最小基线模型,Mv3-SCDn炮孔检测模型参数量下降了7.17%,检测速度提高了45.44%,具有网络模型参数量小、检测速度快和计算性能更好的优点,显著低于本质安全型边缘计算设备的功耗限制,实现了模型的轻量化。笔者的CUMTB-BID数据集采自于安徽省淮南市某矿工作面,包含4 985张图像和标签,为提高笔者装药机械臂智能化控制系统中的炮孔图像检测算法在不同掘进工作面中应用的鲁棒性,还需要进一步采集多种不同掘进工作面的图像作为数据集,丰富数据集种类,训练更加鲁棒的炮孔检测模型,以满足更复杂场景下的应用需求。
-
![]()
图 1 轻量化炮孔检测与定位算法Mv3-SCD结构
Figure 1. Lightweight blasthole detection and localization algorithm Mv3-SCD structure
![]()
图 4 不同条件下采集的部分样本
Figure 4. Part of the sample maps collected under different conditions
表 1 检测分支输出结果
Table 1 Detection branch output results
检测头 检测分支 输出 YOLOv8 P3 80×80×256 P4 40×40×512 P5 20×20×1 024 Ours P2 160×160×128 P3 80×80×256 P4 40×40×512  下载: 导出CSV
下载: 导出CSV
表 2 客观指标对比结果
Table 2 Objective index comparison results
模型 参数量/M mAP@0.5/% mAP@0.5_0.95/% 每秒帧数 YOLOv8n 3.110 79.8 41.6 108.31 Mv3-SCD-nano 2.887 89.7 45.8 157.53 YOLOv8s 11.126 82.5 42.7 105.29 Mv3-SCD-small 10.578 90.6 44.9 132.78 YOLOv8m 25.840 83.9 44.6 98.75 Mv3-SCD-medium 23.273 90.9 45.3 117.28 YOLOv8l 43.631 84.3 45.9 89.98 Mv3-SCD-large 38.194 91.1 46.2 95.84
下载: 导出CSV
表 3 检测头消融实验结果
Table 3 Head ablation experimental results
检测头 输出 mAP@0.5/% mAP@0.5_0.95/% 参数量/M 检测速度/FPS YOLOv8 80×80×256 89.3 45.2 3.110 108.31 40×40×512 20×20×1 024 Ours 160×160×128 89.6 45.8 3.006 113.29 80×80×256 40×40×512
下载: 导出CSV
表 4 模块消融实验结果
Table 4 Module ablation experimental results
Mv3_Block Sc_C2f 空洞金字塔池化模块 MPDIoU 参数量/M mAP@0.5/% mAP@0.5_0.95/% 检测速度/FPS 3.110 79.8 41.6 108.31 √ 3.274 86.8 44.4 132.27 √ 1.821 82.1 43.0 107.47 √ 3.112 85.9 43.9 101.01 √ √ 2.872 86.3 43.7 119.05 √ √ 3.298 89.4 45.1 128.83 √ √ 2.781 85.6 42.8 123.46 √ √ √ 2.981 89.3 44.9 159.67 √ √ √ √ 2.887 89.7 45.8 157.53
下载: 导出CSV
-
[1] 刘峰,曹文君,张建明,等. 我国煤炭工业科技创新进展及“十四五” 发展方向[J]. 煤炭学报,2021,46(1):1−15. LIU Feng, CAO Wenjun, ZHANG Jianming, et al. Current technological innovation and development direction of the 14th five-year plan period in china coal industry[J]. Journal of China Coal Society,2021,46(1):1−15.
[2] Williamson, Kathryn et al. “Embedding Climate Change Engagement in Astronomy Education and Research. ” arXiv:Instrumentation and Methods for Astrophysics (2019).
[3] 王国法,张良,李首滨,等. 煤矿无人化智能开采系统理论与技术研发进展[J]. 煤炭学报,2023,48(1):34−53. WANG Guofa, ZHANG Liang, LI Shoubin, et al. Progress in research and development of theory and technology of unmanned intelligent mining system in coal mine[J]. Journal of China Coal Society,2023,48(1):34−53.
[4] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. NJ:IEEE, 2014:580−587.
[5] GIRSHICK R. Fast R-CNN. Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago:IEEE, 2015:1440−1448.
[6] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137−1149. doi: 10.1109/TPAMI.2016.2577031
[7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once:Unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ:IEEE, 2016:779−788.
[8] REDMON J, FARHADI A. YOLO9000:Better, faster, stronger[C]. NJ:IEEE, 2017:6517−6525.
[9] REDMON J, FARHADI A. YOLOv3:An incremental improvement[EB/OL]. 2018:1804.02767. https://arxiv.org/abs/1804.02767v1.
[10] BOCHKOVSKIY A, WANG C Y, LIAO H M. YOLOv4:Optimal speed and accuracy of object detection[EB/OL]. 2020:2004.10934. https://arxiv.org/abs/2004.10934v1.
[11] LI Chuyi, LI Lulu, JIANG Hongliang, et al. YOLOv6:A Single-Stage Object Detection Framework for Industrial Applications[J]. arXiv:2209.02976, 2022.
[12] WANG C Y, BOCHKOVSKIY A, LIAO H M. YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[EB/OL]. 2022:2207.02696. https://arxiv.org/abs/2207.02696v1.
[13] WANG G F, REN H W, ZHAO G R, et al. Research and practice of intelligent coal mine technology systems in China[J]. International Journal of Coal Science & Technology,2022,9(1):24.
[14] 张也. 智能炸药填装机器人炮孔识别与可行区域规划相关技术研究[D]. 鞍山:辽宁科技大学,2020. ZHANG Ye. Research on blast hole identification of intelligent explosive filling robot and passable area planning[D]. Anshan:University of Science and Technology Liaoning, 2020.
[15] 陈应显,周萌. 基于智能岩性识别的炮孔装药量计算[J]. 爆破,2022,39(4):92−99. doi: 10.3963/j.issn.1001-487X.2022.04.012 CHEN Yingxian, ZHOU Meng. Blasting charge calculation based on intelligent lithology identification[J]. Blasting,2022,39(4):92−99. doi: 10.3963/j.issn.1001-487X.2022.04.012
[16] 郭洪雨,陈宝林,王宇,等. 基于ResUNet网络的隧道围岩图像炮孔留痕检测方法[J]. 水利与建筑工程学报,2020,18(6):158−164. doi: 10.3969/j.issn.1672-1144.2020.06.027 GUO Hongyu, CHEN Baolin, WANG Yu, et al. Blast-hole mark rate detection in surrounding rock image based on ResUNet[J]. Journal of Water Resources and Architectural Engineering,2020,18(6):158−164. doi: 10.3969/j.issn.1672-1144.2020.06.027
[17] 张万志. 岩质隧道炮孔图像识别算法及光面爆破参数优化研究[D]. 济南:山东大学,2019. ZHANG Wanzhi. Study on image recognition algorithm of borehole in rock tunnel and optimization of smooth blasting parameters[D]. Jinan:Shandong University, 2019.
[18] 苏钰桐,杨炜毅,李俊霖. 基于YOLO v3的煤岩钻孔图像裂隙智能识别方法[J]. 煤矿安全,2021,52(4):156−161. SU Yutong, YANG Weiyi, LI Junlin. Intelligent recognition method of borehole image fractures for coal and rock based on YOLO v3[J]. Safety in Coal Mines,2021,52(4):156−161.
[19] ZHANG Z Y, DENG H G, LIU Y, et al. A semi-supervised semantic segmentation method for blast-hole detection[J]. Symmetry,2022,14(4):653. doi: 10.3390/sym14040653
[20] AKINLAR C, TOPAL C. EDCircles:A real-time circle detector with a false detection control[J]. Pattern Recognition,2013,46(3):725−740. doi: 10.1016/j.patcog.2012.09.020
[21] ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ:IEEE, 2017:6230-6239.
[22] 岳中文,金庆雨,潘杉,等. 基于深度学习的轻量化炮孔智能检测方法研究[J]. 煤炭学报,2024,49(5):2247−2256. [23] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab:Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2018,40(4):834−848. doi: 10.1109/TPAMI.2017.2699184
[24] JOCHER G, CHAURASIA A, QIU J. (2023). Ultralytics YOLO (Version 8.0. 0) [Computer software]. https://github.com /ultralytics.
[25] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM,2017,60(6):84−90. doi: 10.1145/3065386
[26] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ:IEEE, 2016:770−778.
[27] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words:Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[28] WANG S N, LI B Z, KHABSA M, et al. Linformer:Self-attention with linear complexity[EB/OL]. 2020:2006.04768. https://arxiv.org/abs/2006.04768v3.
[29] LI J F, WEN Y, HE L H. SCConv:Spatial and channel reconstruction convolution for feature redundancy[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ:IEEE, 2023:6153−6162.
[30] GUO X Y, YANG K, YANG W K, et al. Group-wise correlation stereo network[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019:3273-3282.
[31] CHEN J R, KAO S H, HE H, et al. Run, don’t walk:Chasing higher FLOPS for faster neural networks[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ:IEEE, 2023:12021−12031.
[32] MA S L, XU Y, MA S L, et al. MPDIoU:A loss for efficient and accurate bounding box regression[EB/OL]. 2023:2307.07662. https://arxiv.org/abs/2307.07662v1.


计量
- 文章访问数: 110
- HTML全文浏览量: 14
- PDF下载量: 33
